“El ingenioso hidalgo don Quijote de la Mancha”, in English translated as _“The Ingenious Nobleman Sir Quixote of La Mancha” or simply “Don Quixote”, is one of the classical novels from the Spanish literature written by Cervantes in the 17th century. The style of the original book is rather difficult to read these days as it is written in a form of old castilian, and certainly even more difficult to emulate for someone living in the 21st century. Can we use deep learning to solve this problem? The answer is YES!
The text of the book El Quijote is freely available in The Project Gutenberg. I used chapters 1 to 10, with roughly 110k characters and 20k words.
The model: a recurrent neural network with 3 layers of LSTM
The model takes as input a sequence of characters, say 100 characters. The goal of the model is to predict the next character. After fitting the model to the training data, we sequentially produce ‘predictions’ of characters so that new words and full sentences are generated.
Input
The training data is sliced so that, for each each training sample, X is a column vector of 100 dimensions and Y is a single item. Here there are the first observations:
| X(m) | Y(m) |
|---|---|
| ‘primera parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condi’ | ‘c’ |
| ‘rimera parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condic’ | ‘i’ |
| ‘imera parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condici’ | ‘o’ |
| ‘mera parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condicio’ | ‘n’ |
| ‘era parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condicion’ | ’ ‘ |
| ‘ra parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condicion ‘ | ‘y’ |
| ‘a parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condicion y’ | ’ ‘ |
| ’ parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condicion y ‘ | ‘e’ |
| ‘parte del ingenioso hidalgo don quijote de la mancha\ncapitulo primero. que trata de la condicion y e’ | ‘j’ |
| … | … |
Note several things:
- The character at Y(m) is the same as the last character in the X(m+1) training sample
- Special characters like ‘\n’ and punctuation signs are also included. We expect the model to be able to generate such characters
- Mathematical models do not understand of characters. Instead, we convert them to numbers before feeding them to the model
The model
The basic block of the model is a Long-Short Term Memory (LSTM)[https://en.wikipedia.org/wiki/Long_short-term_memory] block. LSTM-based models have proved to work really well in practice thanks to their forgetting and updating capabilities. Here it is a quick summary of the components of a LSTM block:
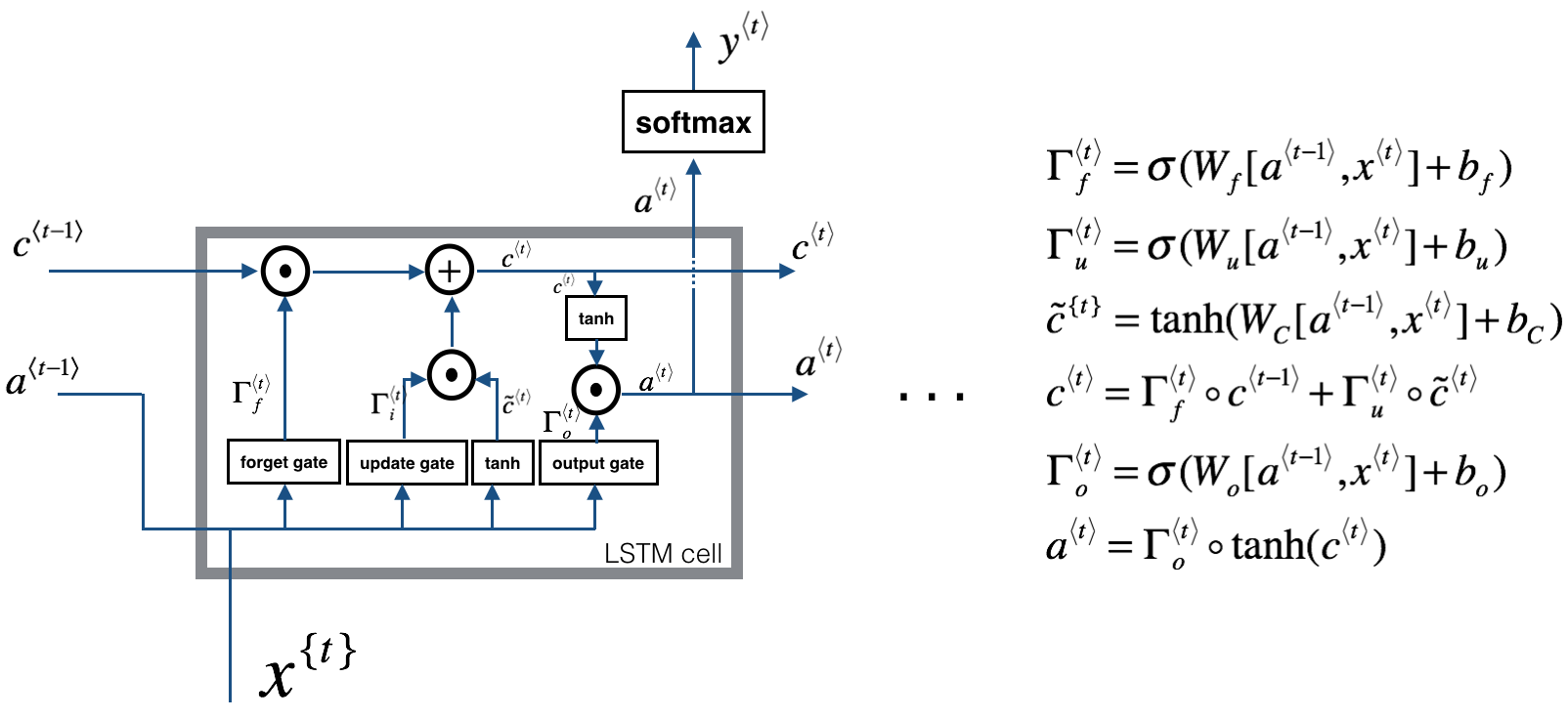
For the Don Quixote we stack 3 LSTM layers with a dropout layer in between. A dropout layer basically randomly “switches off” some neurons at each pass of the optimization algorithm, making the model less prone to over-fitting. In Keras (Python), the model is defined as follows:
# define the LSTM model
model = Sequential()
model.add(LSTM(512, input_shape=(X.shape[1], X.shape[2]),return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(512,return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(512))
model.add(Dropout(0.5))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
The rest of the code is publicly available in this repository.
Generating sequences of (possibly new) words
For generating sequences we do the following:
- Select a random seed. Basically pick a location at random in the book and select the 100 next characters
- Remember that 1 character corresponds to 1 number
- Also remember to normalize the inputs to the model to avoid scaling issues
- Make a prediction. We obtain an array of probabilities of each character appearing next
- Sample from that distribution. A small trick is done so that characters relatively high probability are most likely selected. If we choose the character with the highest probability then we would be sampling the most likely sequence of characters!
- Append this newly generated character to the sequence. Repeat steps 2-4
The above, translated to Python:
def generate_words(model,chars,n_vocab, dataX,seq_length):
# backward dictionary
int_to_char = dict((i, c) for i, c in enumerate(chars))
# pick a random seed
start = np.random.randint(0, len(dataX)-1)
pattern = dataX[start]
print("Seed:")
print("\"", ''.join([int_to_char[value] for value in pattern]), "\"")
# generate characters
for i in range(3000):
# Select latest sequence
pattern_aux = pattern[(len(pattern) - seq_length):len(pattern)]
x = np.reshape(pattern_aux, (1, len(pattern_aux), 1))
x = x / float(n_vocab)
# Predict probability of character appearing next
prediction = model.predict(x, verbose=0)
# Sample
index = sample(prediction[0],0.5)
# add new element
pattern.append(index)
# Translate index to char
seq_in = [int_to_char[value] for value in pattern]
print('\nGenerated text:\n')
print(''.join(seq_in))
print('\n\t*** THE END ***')
return seq_in
Running the main file as follows generates new words:
python3 DonQuijote.py -w weights-improvement-3L-512-23-1.2375.hdf5
An example of the output (takes around 1 minute to generate):
con todo eso, se le dejaron de ser su romance v me dejase, porque no le dejare y facilidad de su modo
que de la lanza en la caballeriza, por el mesmo camino, y la donde se le habia de haber de los que el campo,
porque el estaba la cabeza que le parece a le puerto y de contento, son de la primera entre algunas cosas
de la venta, con tanta furia de su primer algunos que a los caballeros andantes a su lanza, y, aunque
el no puede le dios te parecian y a tu parte, se dios ser puede los viera en la caballeria en la
caballeria en altas partes de la mancha,
It is surprisingly good! Some thoughts:
- The style of the book is definitely really similar to Cervantes style. Some sentences are really funny.
- The syntax, however, is not correct: (…) se le dejaron de ser su romance (…) is wrong even though the words do exist
- Some of the generated words do not exist, even though it is not very often. This indicates the model is working pretty well.
Generating sequences of existing words
A minor modification to the generating algorithm is done such that the newly generated words must exist in the book. If not, that word is rejected. The process is repeated until reasonable words are generated.
python3 DonQuijote.py -w weights-improvement-3L-512-23-1.2375.hdf5 -o True
al cual le parecieron don quijote de la mancha, en cuando le daba a le senor tio en el corral, y tio que andaba muy
acerto los dos viejos, y, al caso de van manera con el de tu escudero. don quijote y mas venta a su asno, con toda
su amo pasa dios de la caballeria y de al que habia leido, no habia de ser tu escudero: la suelo del camino de la
venta, de que san caballo de los que le habia dejado; a este libro es este es el mismo coche, como te ve don mucho
deseos de los que el caballero le hallaba; y al corral con la cabeza que aquel sabio en la gente de la lanza
y tan las demas y camas de tu escudero,
With this modification, the character-generating model can now generate words with a correct syntax.
Training on FloydHub
FloydHub is a cloud-based platform for training and deploying deep learning models. It is really easy and straightforward to use. Here it is a quick guide on how you can train your models with only a few lines of code:
- First you need to create an account
- Install their command-line tool and login
pip3 install -U floyd-cli floyd login - Create a project
- Go to the folder where the code is ans initialize the project:
cd DonQuijote_RNN floyd init DonQuijote_RNN - Run a script that trains the model and saves the weights on a folder
floyd run --gpu --env tensorflow-1.3 "python3 DonQuijote.py"The model has been trained on a 61 GB GPU for roughly 5 hours. The weights of the model are updated to the repository.
Further ideas on how to improve the model
- Train for longer epochs with a bigger training set. This is a safe way of getting better results.
- Implement a beam search algorithm character-wise.
- Model whole words instead of characters. This will certainly generate more sensible sentences.
- Generate full sentences with a bi-directional RNN.
- Apply a pre-trained embedding matrix (word2vec for example), even though with an old-style of writing as Don Quijote it will most likely not work very well